
Assistive Visual Navigation
2025
PI: Dr. Abolfazl Razi arazi@clemson.edu
Project Overview
Assistive visual navigation systems for visually impaired individuals have become increasingly popular thanks to the rise of mobile computing. Most of these devices work by translating visual information into voice commands. In complex scenarios where multiple objects are present, it is imperative to prioritize object detection and provide immediate notifications for key entities in specific directions. This brings the need for identifying the observer’s motion direction (ego-motion) by merely processing visual information, which is the key contribution of this project.
See our poster/paper at the BSN 2024: BSN 2024 Poster / Paper
See our project page for the practical implementation and testing: AIS-Clemson/MotorFocus
(2025) VIA-LLM: Visually Impaired Assistive Tool with LLM Reasoning (under developing)
Globally, over two billion people suffer from vision impairment, with approximately 43 million classified as legally blind. Some eye diseases, such as Retinitis Pigmentosa (RP), lead to gradual vision loss and currently have no cure. Most treatments for such genetics-driven diseases – including gene therapy (e.g., Luxturna for specific mutations), stem cells, artificial retinal implants, and vitamin A supplementation – have shown only minor effects in restoring lost vision and remain in exploratory stages for decades. For such conditions, developing assistive tools arises as a promising alternative to enable patients to manage their daily tasks and live more independently.
Computer Vision
To assist visually impaired users in perceiving their surroundings, we integrate real-time computer vision capabilities. Our system captures live video from a user-worn camera and processes the stream to identify objects, detect motion patterns, and simulate various vision impairment conditions. These capabilities form the foundation for further semantic reasoning and audio-based feedback generation.
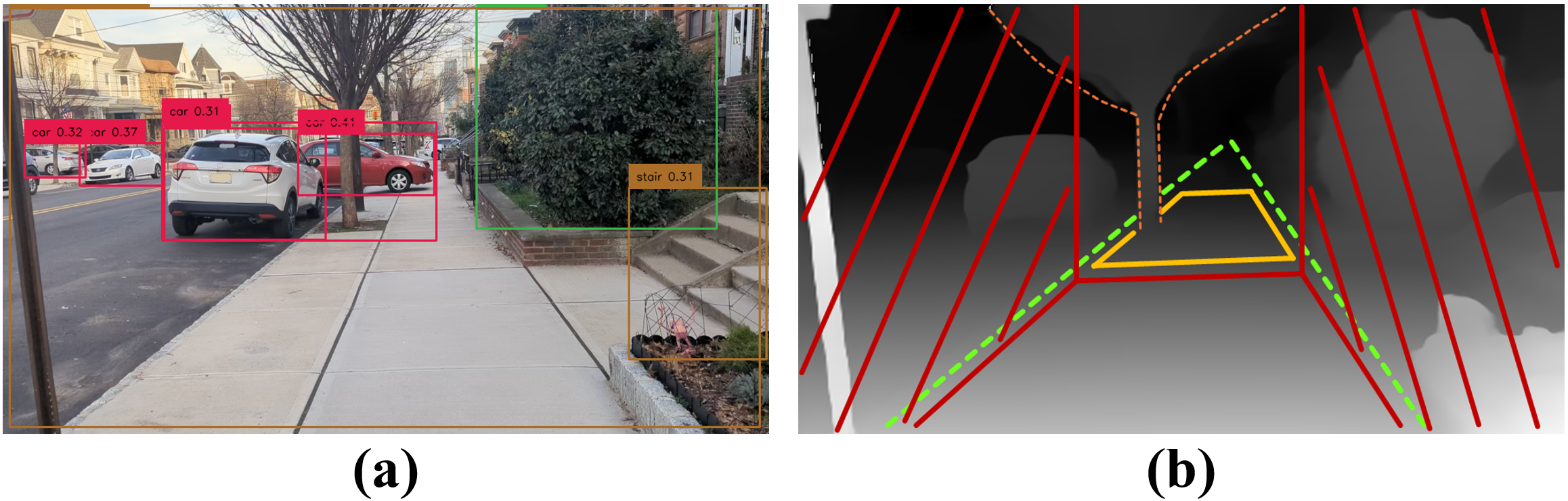
Object detection/segmentation
We apply state-of-the-art object detection and segmentation models YOLO to identify and localize important entities within the user’s environment. These include dynamic obstacles (e.g., vehicles, people) and static infrastructure (e.g., staircases, signboards). The detected objects are then analyzed for spatial layout, proximity, and potential interaction, enabling context-aware guidance and warnings.

Motion-based analysis
In complex, dynamic scenes, recognizing motion is critical for timely intervention. Our system tracks moving objects and analyzes their trajectories to predict potential collisions or abnormal behaviors (e.g., a person running against the flow). This allows the agent to prioritize hazards and issue real-time alerts, even in crowded urban settings.

Simulated visual impairment-sensing
“Less is better.” To understand the visual limitations of different eye diseases, we simulate vision loss scenarios such as tunnel vision, blurred vision, or night blindness. These simulations help us evaluate the system’s effectiveness under various impairment models and guide the design of compensation strategies such as auditory cues or zoomed-in focus detection.

Assistive agent
Beyond perception, VIA-LLM incorporates reasoning and interaction modules that bridge the gap between raw visual data and meaningful user feedback. Using large language models, the system can interpret scene context, anticipate risks, and generate natural-language responses for real-time assistance.
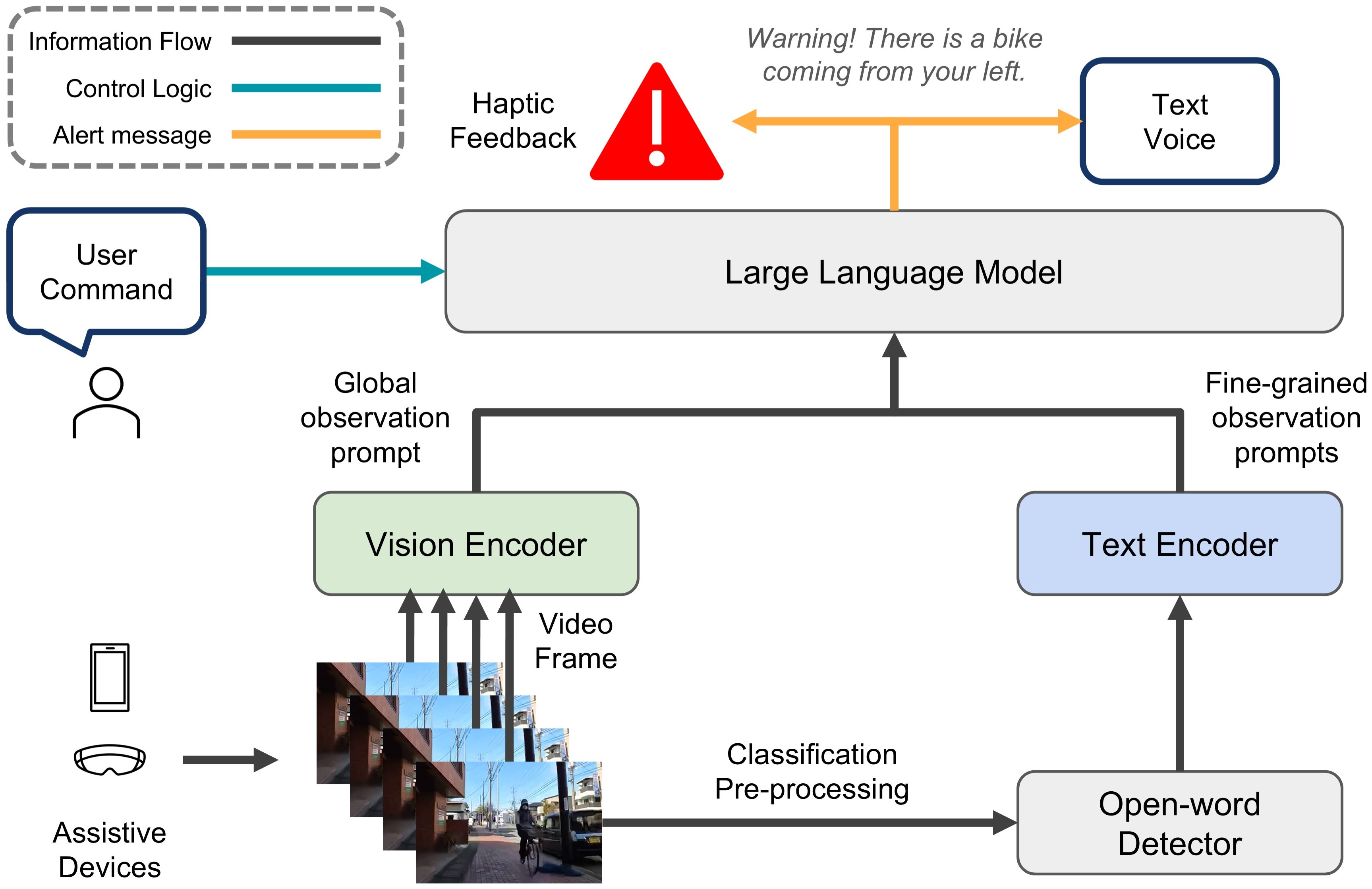
Early detection & feedback
The system continuously monitors the scene to detect potentially hazardous situations in advance—such as a fast-approaching vehicle or an unexpected object on the path. It prioritizes urgency and relevance, enabling timely and intuitive feedback to the user through auditory signals or haptic cues.

Voice boardcast & alert
To maximize accessibility, our system employs a voice-based interface to broadcast situational awareness updates and urgent alerts. For example, it can announce, “Crosswalk ahead, wait for green light,” or “Bicycle approaching from the left.” This interactive voice feedback, powered by LLM-driven semantic analysis, ensures that users are not overwhelmed by raw data but instead receive concise, contextually relevant guidance.

(2024) Ego-Motion Prediction with All-Pixel Matching
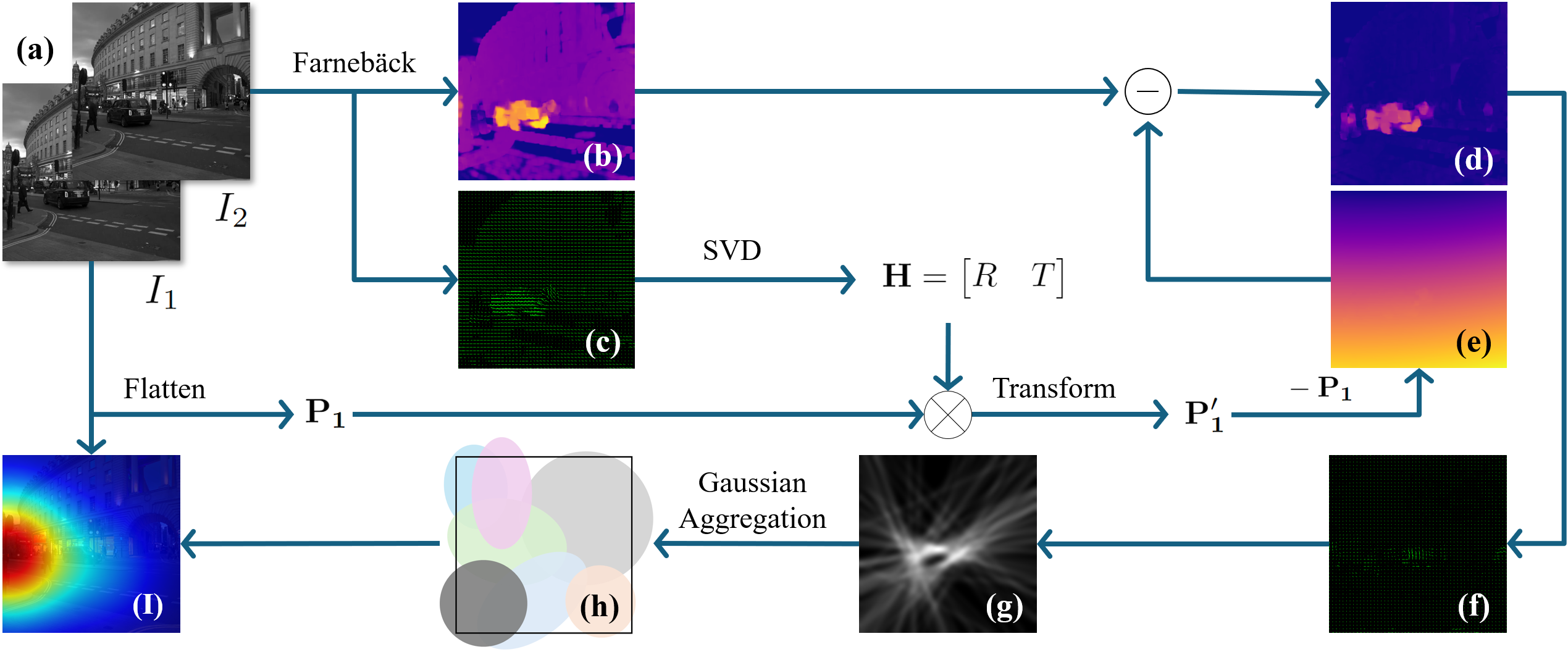
This project introduces Motor Focus – a lightweight, image-based framework designed to predict ego-motion, i.e., the movement intentions of humans (or humanoid machines), using visual input while filtering out camera motion without the need for camera calibration. The framework implements an optical flow-based pixel-wise temporal analysis to account for camera movement, enhanced by a Gaussian aggregation to smooth the predicted movement area.


Features
Our framework mainly predicts ego-motion by identifying how users physically orient themselves in space through pixel-wise temporal analysis.
- Video Stabilization: To counteract camera shake, we used SVD and optical flow to estimate the affine transformation matrix from feature points extracted in two consecutive frames.
- Camera Motion Compensation: The fusion of two consecutive frames filters the camera motion, which highlights the object that moves relatively with the observer.

Dataset
This project also included custom datasets that are collected to train/test assistive visual navigation.

Acknowledgements:
Please cite our work if you find this project helpful.
@inproceedings{wang2024motor,
title={Motor Focus: Fast Ego-Motion Prediction for Assistive Visual Navigation},
author={Wang, Hao and Qin, Jiayou and Chen, Xiwen and Bastola, Ashish and Suchanek, John and Gong, Zihao and Razi, Abolfazl},
booktitle={2024 IEEE 20th International Conference on Body Sensor Networks (BSN)},
pages={1--4},
year={2024},
organization={IEEE}
}
(2024) VisionGPT: LLM-Assisted Real-Time Anomaly Detection for Safe Visual Navigation
Demonstration
Overview
This project explores the potential of Large Language Models(LLMs) in zero-shot anomaly detection for safe visual navigation.
See our another project for the movement prediction: H-Splitter
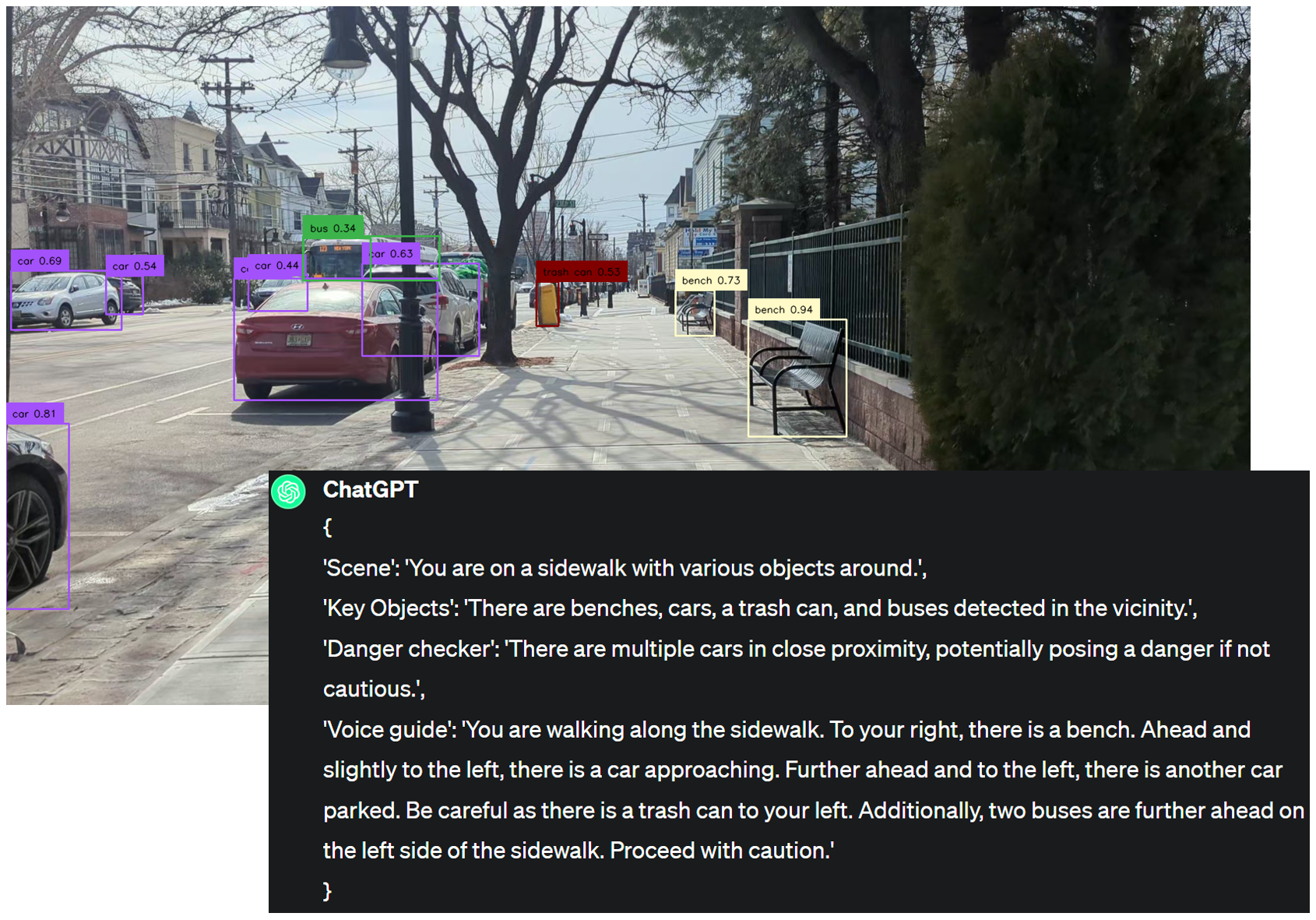
With the assistance of state-of-the-art real-time open-world object detection model Yolo-World and specialized prompts, the proposed framework can identify anomalies within camera-captured frames that include any possible obstacles, then generate concise, audio-delivered descriptions emphasizing abnormalities, assist in safe visual navigation in complex circumstances.
Moreover, our proposed framework leverages the advantages of LLMs and the open-vocabulary object detection model to achieve the dynamic scenario switch, which allows users to transition smoothly from scene to scene, which addresses the limitation of traditional visual navigation.
Furthermore, this project explored the performance contribution of different prompt components provided the vision for future improvement in visual accessibility and paved the way for LLMs in video anomaly detection and vision-language understanding.
Method
Yolo-World
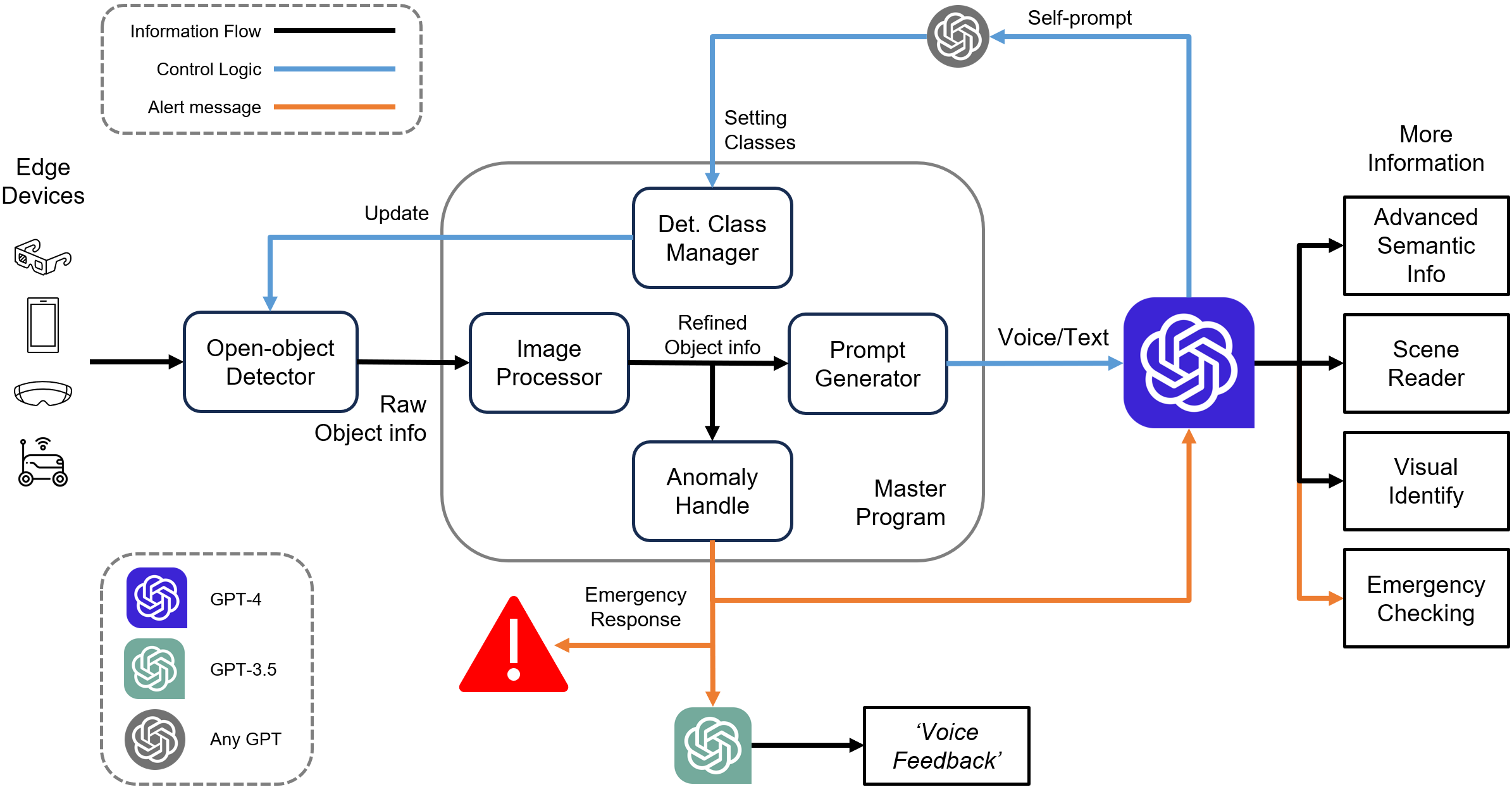
We apply the latest Yolo-world for the open-world object detection task to adapt the system in any scenario any situation. The detection classes are generated by GPT-4 and can be replaced dynamically.
GPT-3.5
We apply GPT-3.5 for fast response and low cost. We have tested GPT-4 and GPT-4V but found them not financial-friendly.
H-splitter
We implemented an H-splitter to assist object detection and categorize the objects into 3 different types based on the priority.

See our another project for more info: H-Splitter
Experiments
We use Yolo-World with the H-splitter for universal object detection. For any object that falls (a)in Area 3 or (b)in Area 1/2 with 15% of window size, we record the corresponding frame as anomalies. We set this Yolo-World-H setting as the ground truth for the benchmark.
System Sensitivity
We pre-set the system with 3 different sensitivities to report the emergency: low, normal, and high. We find that the low system sensitivity is good for daily use due to the low false alarm rate.
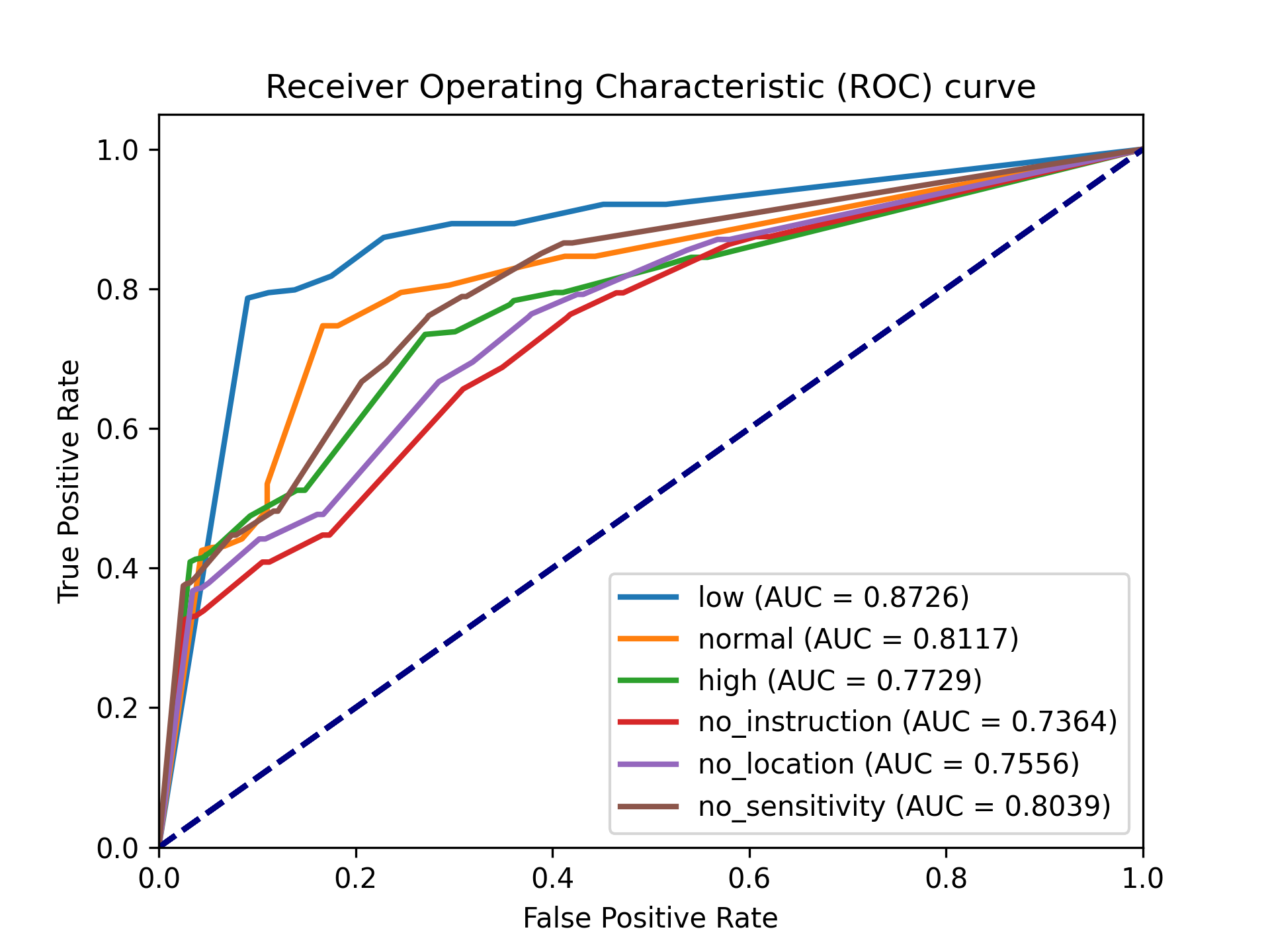
Detection accuracy
We compare the VisionGPT with low system sensitivity with the ground truth to evaluate its performance. We find that VisionGPT has high Accuracy and prefers less False Positive (unnecessary reports).
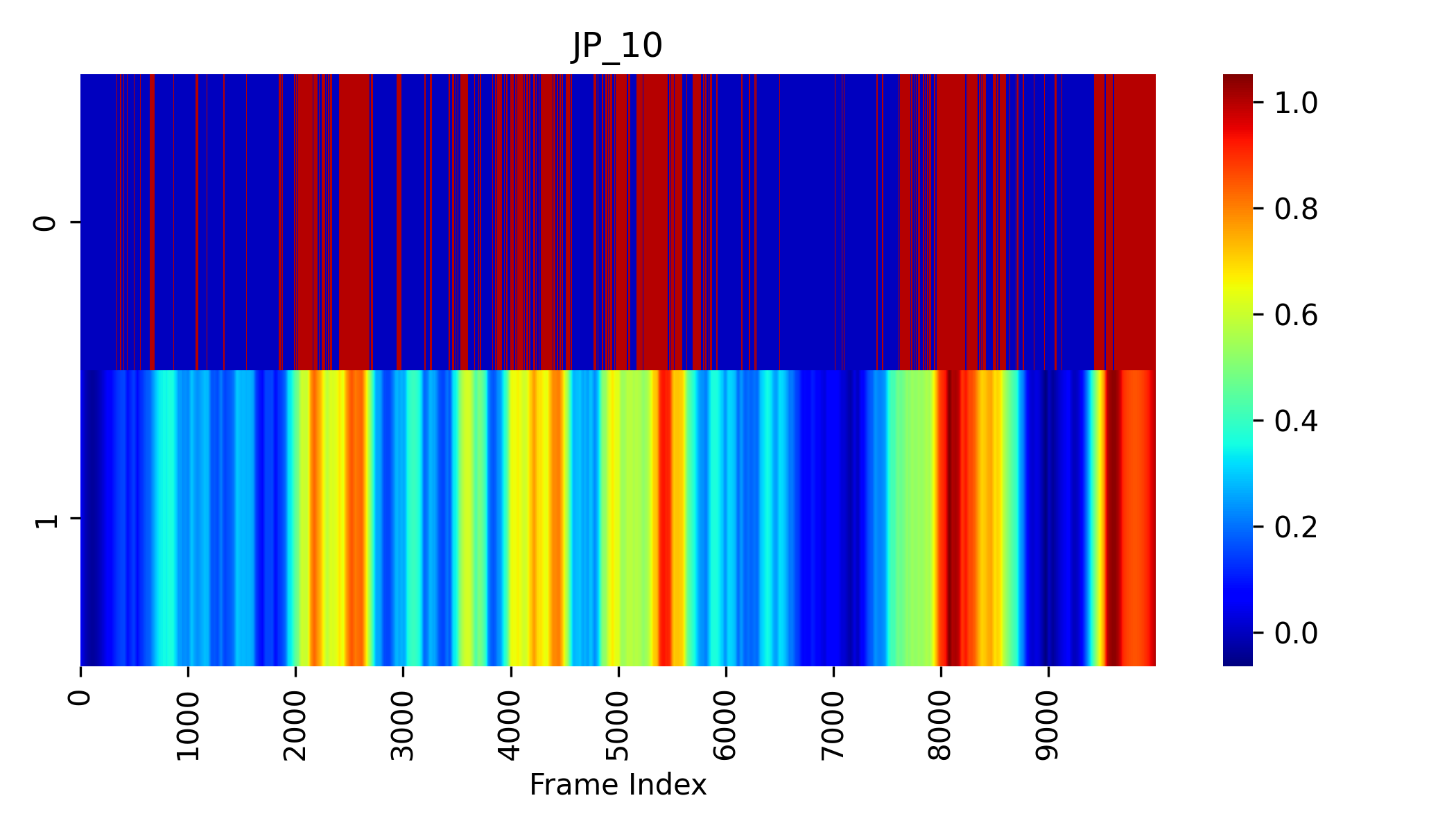
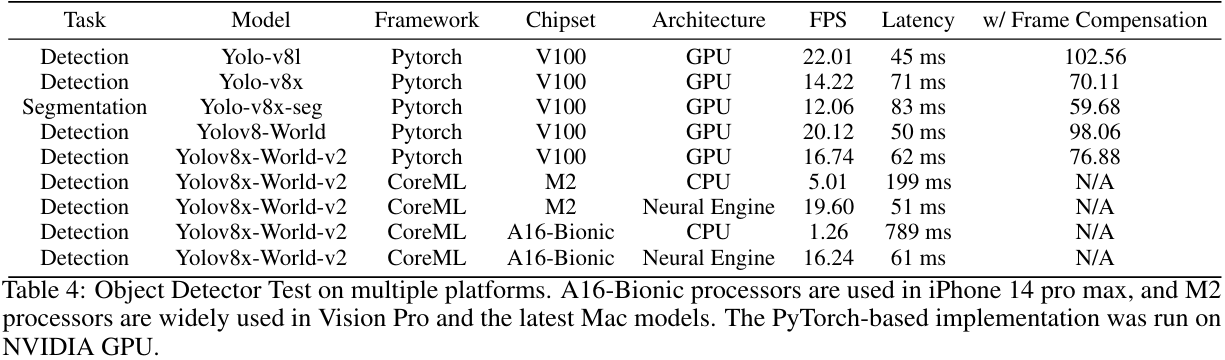
System Performance & Compatibility
Cost Evaluation

Acknowledgements:
Please cite our work if you find this project helpful.
@article{wang2024visiongpt,
title={VisionGPT: LLM-Assisted Real-Time Anomaly Detection for Safe Visual Navigation},
author={Wang, Hao and Qin, Jiayou and Bastola, Ashish and Chen, Xiwen and Suchanek, John and Gong, Zihao and Razi, Abolfazl},
journal={arXiv preprint arXiv:2403.12415},
year={2024}
}
Outcomes
Conference Proceedings:
- Spatial-Conditioned Reasoning in Long-Egocentric Videos
- Motion Focus Recognition in Fast-Moving Egocentric Video (WACV2026@CV4WS)
- Motor Focus: Fast Ego-Motion Prediction for Assistive Visual Navigation (BSN2024)
Codes
Project Team
PI: Dr. Abolfazl Razi arazi@clemson.edu
Graduate Students:
- Hao Wang
- Xiwen Chen
- Ashish Bastola
Undergraduate Students:
- John Suchanek
Acknowledgements:
Research reported in this project was supported in part by the NSF and SC EPSCoR Program under award number (NSF Award # OIA-2242812 and SC EPSCoR 26-CRP03). The views, perspective, and content do not necessarily represent the official views of the SC EPSCoR Program nor those of the NSF.